1. 什么是HTTPS?
1.1 HTTPS的解释
HTTPS(Hypertext Transfer Protocol Secure)是HTTP协议的安全版本。它通过在HTTP和TCP之间添加一个安全层(通常是SSL/TLS),来确保数据在传输过程中的机密性和完整性。HTTPS主要用于保护敏感信息,如用户登录凭证、信用卡信息等,防止这些数据在传输过程中被窃取或篡改。
1.2 HTTPS与HTTP的区别
HTTPS和HTTP的主要区别包括:
- 安全性:HTTPS通过加密传输的数据,提供了更高的安全性,而HTTP传输的数据是明文的。
- 端口:HTTPS默认使用443端口,HTTP默认使用80端口。
- URL前缀:HTTPS的URL以”https://“开头,HTTP的URL以”http://“开头。
2. 什么是PKI?
2.1 PKI的定义
PKI(Public Key Infrastructure,公钥基础设施)是一个用于创建、管理、分发、使用、存储和撤销数字证书的系统。它提供了一个框架,使得在不安全的网络中,如互联网,可以安全地进行电子交易。PKI的核心是基于非对称加密技术,它使用一对密钥:公钥和私钥。公钥可以自由分发,而私钥则由所有者秘密保管。PKI通过数字证书来建立身份的可信度,这些证书由被称为证书颁发机构(CA)的可信第三方签发。
2.2 PKI的组件
PKI的主要组件包括:
- 证书颁发机构(CA):负责签发和管理数字证书
- 注册机构(RA):验证证书申请者的身份
- 证书存储库:存储和分发证书及证书撤销列表(CRL)
- 密钥对:包括公钥和私钥
- 终端实体:证书的使用者,如个人、组织或设备
2.3 每个组件在建立信任中的角色
在PKI中,每个组件在建立信任过程中扮演着不同但相互关联的角色:
- 证书颁发机构(CA):作为信任的根源,CA负责验证申请者的身份,并签发数字证书,从而建立可信的身份认证体系。
- 注册机构(RA):作为CA的代理,RA负责收集和验证证书申请者的信息,确保申请者的身份真实可靠,从而支持CA的信任决策。
- 证书存储库:通过提供证书和证书撤销列表的公开访问,使得依赖方能够验证证书的有效性,从而维护整个PKI系统的信任状态。
- 密钥对:公钥用于加密数据和验证数字签名,私钥用于解密数据和创建数字签名,共同构成了PKI中的加密和身份验证基础。
- 终端实体:作为证书的实际使用者,终端实体通过使用其数字证书来证明自己的身份,从而在网络通信中建立可信的关系。
2.4 数字证书和证书链
在PKI系统中,数字证书是一种电子文档,用于证明公钥的所有权。它包含了公钥、所有者的身份信息以及颁发机构的数字签名。数字证书的主要作用是建立一个可信的身份验证机制,确保通信双方的身份真实可靠。证书通常遵循X.509标准,包含诸如版本号、序列号、签名算法、颁发者、有效期、主体、公钥信息等字段。
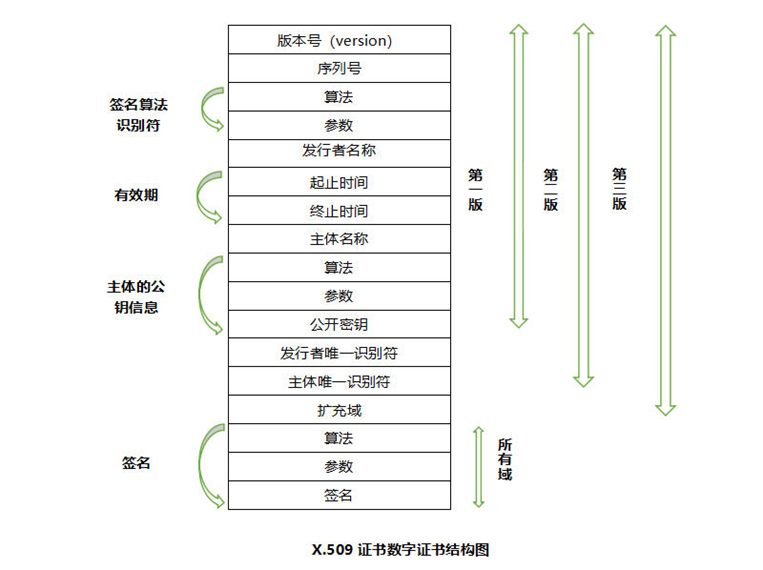
数字签名是为了确保数据发送者的合法身份,也可以确保数据内容未遭到篡改,保证数据完整性。与手写签名不同的是,数字签名会随着文本数据的变化而变化。具体到数字证书的应用场景,数字签名的生成和验证流程如下:
- 服务器对证书内容进行信息摘要计算(常用算法有 SHA-256 等),得到摘要信息,然后用私钥加密该摘要信息,生成数字签名。
- 服务器将数字证书和数字签名一起发送给客户端。
- 客户端使用公钥解密数字签名,获得摘要信息。
- 客户端使用相同的信息摘要算法重新计算证书的摘要信息,然后将两个摘要信息进行比对。如果相同,则证明证书未被篡改;否则,证书验证失败。
证书链是PKI系统中用于建立信任的重要机制。它是一系列数字证书的集合,从终端实体的证书开始,通过一个或多个中间证书颁发机构(CA)的证书,最终连接到根CA的证书。这种链式结构允许验证者通过追溯证书链来确认一个证书的有效性和可信度。在实际应用中,证书链的验证过程是自动进行的,通常由浏览器或操作系统完成,为用户提供了无缝的安全体验。
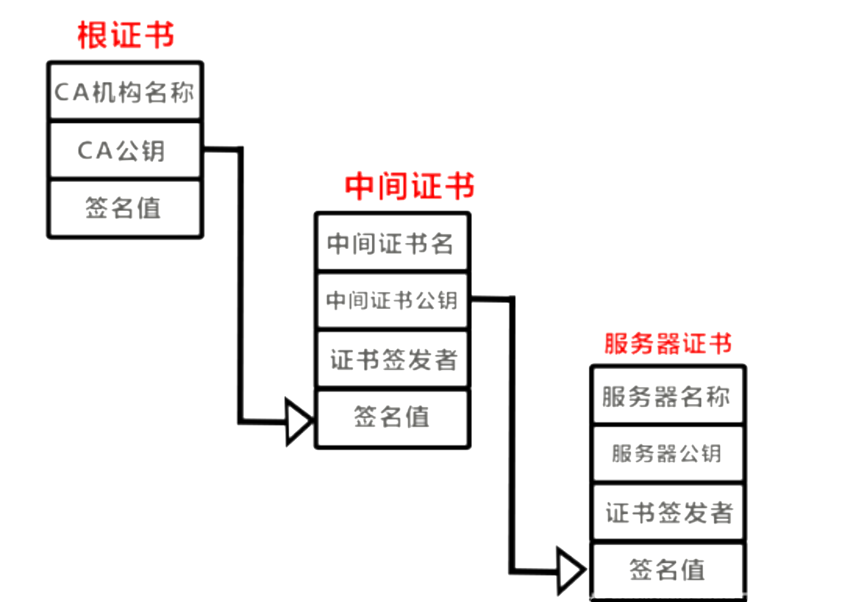
3. PKI如何与HTTPS配合工作?
3.1 SSL/TLS协议的解释
SSL/TLS(Secure Sockets Layer/Transport Layer Security)是一种加密协议,用于在互联网上安全地传输数据。它在应用层和传输层之间提供了一个安全层,确保了数据的机密性、完整性和认证。SSL是TLS的前身,虽然现在通常使用TLS,但人们仍习惯性地将其称为SSL。这个协议通过使用数字证书、公钥加密和对称加密的组合来实现安全通信。
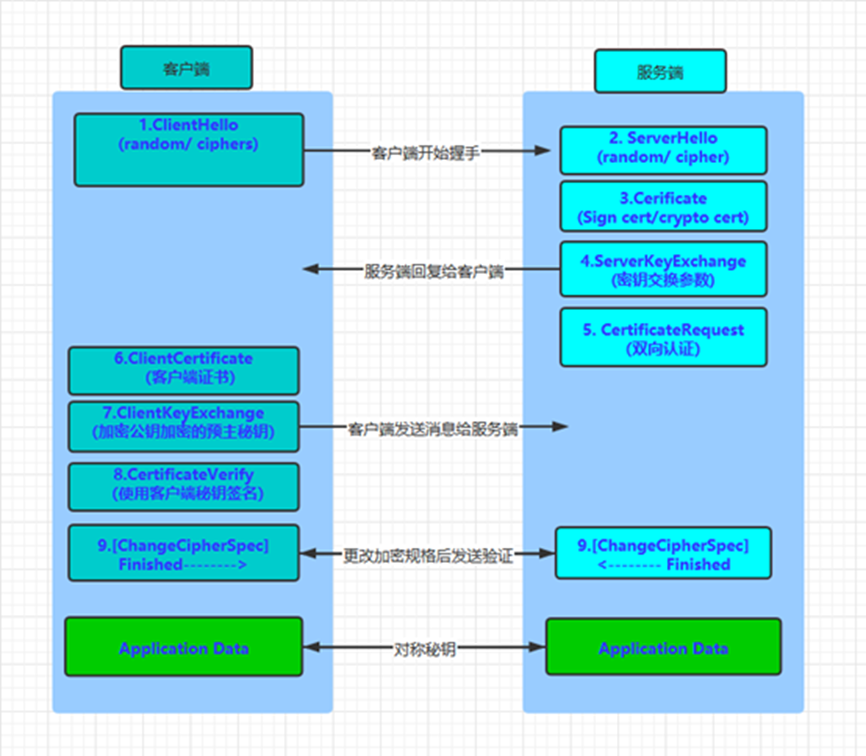
3.2 SSL/TLS握手过程的概述
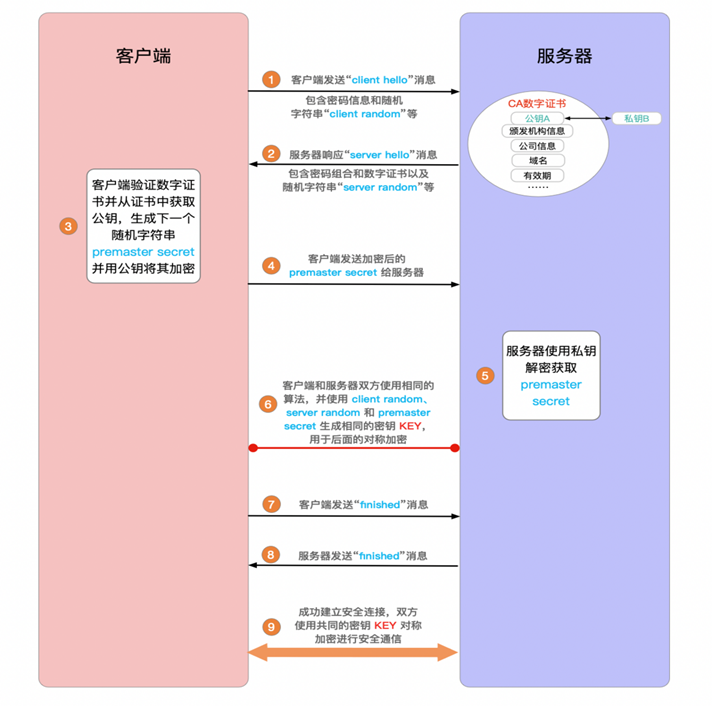
“Client Hello” 消息:客户端通过发送”Client Hello”消息向服务器发起握手请求。该消息包含客户端支持的 TLS 版本、密码套件选项,以及一个”client random”随机字符串。
“Server Hello” 消息:服务器回应”Server Hello”消息,包含数字证书、服务器选择的密码套件和”server random”随机字符串。
验证:客户端验证服务器的证书,确保其身份合法。验证过程包括:
a) 检查数字签名
b) 验证证书链
c) 检查证书有效期
d) 检查证书撤销状态(撤销意味着证书已失效)
“Premaster Secret” 生成:客户端生成”premaster secret”(预主密钥)并用服务器的公钥加密,发送给服务器。只有拥有对应私钥的服务器才能解密。
私钥解密:服务器使用私钥解密”premaster secret”。
会话密钥生成:客户端和服务器使用client random、server random和premaster secret,通过相同算法生成共享的会话密钥KEY。
客户端就绪:客户端发送经会话密钥KEY加密的”Finished”消息。
服务器就绪:服务器也发送经会话密钥KEY加密的”Finished”消息。
安全通信建立:握手完成,双方使用对称加密进行后续安全通信。
3.3** HTTPS **加密、解密、验证及数据传输过程
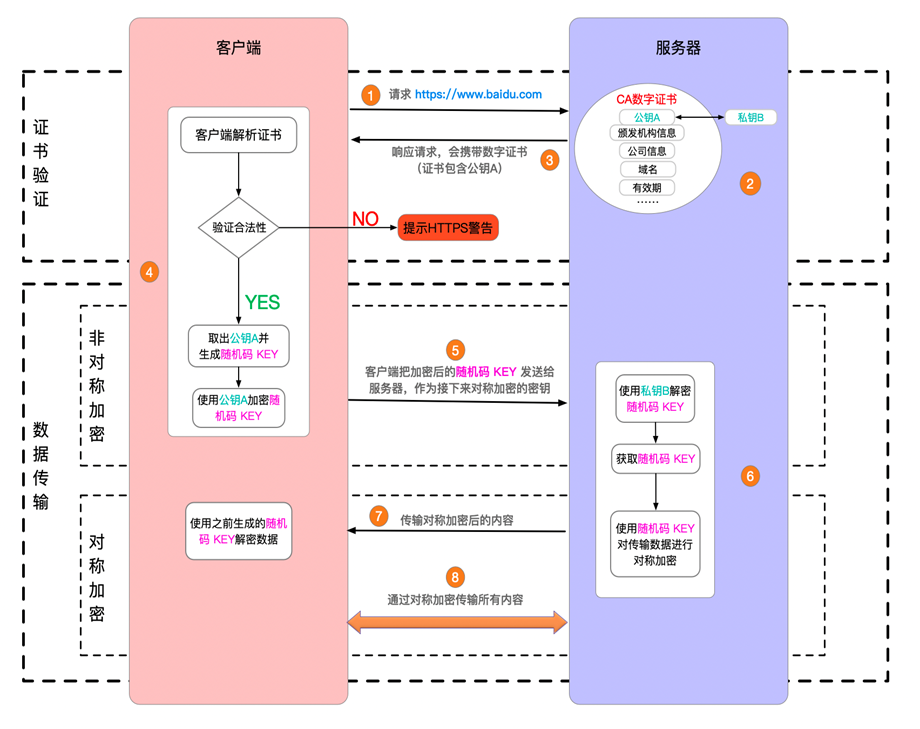
HTTPS 的整个通信过程可分为两大阶段:证书验证和数据传输。数据传输阶段又可细分为非对称加密和对称加密两个阶段。以下是具体流程的讲解:
客户端请求 HTTPS 网址,连接到服务器的 443 端口(HTTPS 默认端口,类似于 HTTP 的 80 端口)。
采用 HTTPS 协议的服务器必须拥有一套数字证书(CA 证书)。这些证书需要申请,由专门的数字证书认证机构(CA)经过严格审核后颁发。证书价格因安全级别而异,级别越高价格越贵。颁发证书时会生成一对密钥:私钥由服务端保密存储,公钥附在证书信息中可公开。证书还包含一个电子签名,用于验证证书的完整性和真实性,防止篡改。
服务器响应客户端请求,将证书传递给客户端。证书包含公钥和其他信息,如证书颁发机构信息、公司信息和有效期等。在 Chrome 浏览器中,点击地址栏的锁图标再点击”证书”可查看详细信息。
客户端解析并验证证书。如果证书不是由可信机构颁发、证书域名与实际域名不符,或证书已过期,客户端会向用户显示警告,由用户决定是否继续通信。这就是”您的连接不是私密连接”的提示原因。
若证书无问题,客户端从中提取服务器的公钥 A,并生成一个随机码 KEY,用公钥 A 加密。
客户端将加密后的随机码 KEY 发送给服务器,作为后续对称加密的密钥。
服务器收到随机码 KEY 后,用私钥 B 解密。至此,客户端和服务器建立了安全连接,解决了对称加密的密钥泄露问题。
服务器使用密钥(随机码 KEY)对数据进行对称加密并发送给客户端,客户端用相同的密钥解密数据。
双方使用对称加密安全地传输所有数据。
4. 如何获取SSL证书?
4.1 SSL证书的类型(扩展验证、组织验证、域验证)
SSL证书主要分为三种类型:
- 扩展验证(EV)证书:提供最高级别的安全性和信任,需要严格的身份验证过程。
- 组织验证(OV)证书:验证申请者的组织和域名所有权,提供中等级别的信任。
- 域名验证(DV)证书:仅验证域名所有权,是最基本的SSL证书类型,通常用于小型网站或个人博客。
这些证书类型在验证过程、颁发速度和价格上有所不同,用户可以根据自身需求选择合适的类型。
4.2 获取和安装SSL证书的步骤
获取和安装SSL证书通常包括以下步骤:
- 选择证书类型和证书颁发机构(CA)
- 生成证书签名请求(CSR)和私钥
- 提交CSR给CA并完成验证过程
- 接收和下载SSL证书
- 在服务器上安装SSL证书和私钥
- 配置服务器以使用SSL/TLS
- 测试SSL配置并确保正常工作
具体步骤可能因CA和服务器类型而略有不同,但总体流程大致相同。
5. 应用案例
5.1 Nginx如何配置SSL?
1 | server { |
5.2 RabbitMQ如何配置SSL?
- 修改配置文件
配置文件/data/rabbitmq/conf.d/10-defaults.conf增加如下示例内容。禁用明文认证方式,启动SSL证书认证。
服务端证书:
ca/cacert.pem #CA证书
server/rabbitmq-server.cert.pem #服务端公钥
server/rabbitmq-server.key.pem #服务端私钥
客户端证书:
client/rabbitmq-client.keycert.p12 #客户端PKCS12证书
client/rabbitmqTrustStore #服务端JKS格式公钥
记录生成证书步骤中生成客户端证书时的密码,客户端应用程序需要。
1 | listeners.ssl.default=5671 |
- 启用SSL插件
进入RabbitMQ容器或服务器实际安装路径,执行以下命令
#启用rabbitmq_auth_mechanism_ssl作为EXTERNAL认证机制的实现
rabbitmq-plugins enable rabbitmq_auth_mechanism_ssl
#查看启动结果
rabbitmq-plugins list
- 添加证书登录用户与授权(重要)
#添加证书登录用户(用户名要与客户端证书名称前缀一致),密码任意
rabbitmqctl add_user 'rabbitmq-client' '1234567'
#给rabbitmq-client用户虚拟主机/的所有权限,如需其他虚拟主机替换/
rabbitmqctl set_permissions -p "/" "rabbitmq-client" ".*" ".*" ".*"
- SpringBoot集成
增加证书后对jdk版本有要求,必须jdk8u330以上
增加RabbitFanoutExchangeConfig.java和配置内容
1 |
|
1 | spring: |
- 证书生成方法
1 | #克隆生成证书的仓库到当前目录 |
5.3 MySQL如何配置SSL?
从MySql服务器的安装目录中取出ca.pem、client-cert.pem、client-key.pem,执行下面三个命令生成SpringBoot客户端所需要的两个证书文件mysqlTrustStore.jks、mysql-client.jks,注意第二个命令和第三个命令用到的密码(标红部分)需要相同。若使用其他客户端可直接用pem文件。
1 | keytool -importcert -alias Cacert -file ca.pem -keystore mysqlTrustStore.jks -storepass 123456 |
SpringBoot配置文件示例,如果是磁盘路径,将classpath:改为file:
1 | ssl: |
6. 国密算法与HTTPS
6.1 国密算法的介绍

6.2 国密算法与HTTPS的结合
国密算法与HTTPS的结合主要体现在以下几个方面:首先,国密算法可以替代传统的RSA和ECC算法,用于HTTPS中的密钥交换和数字签名。其次,国密算法可以作为HTTPS中的对称加密算法,用于加密传输的数据。最后,国密算法还可以用于HTTPS证书的生成和验证,以提高安全性和合规性。